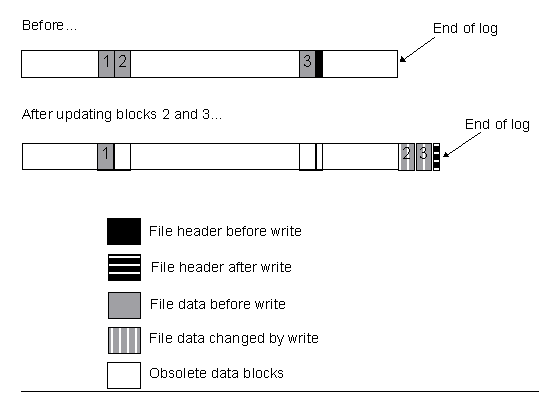
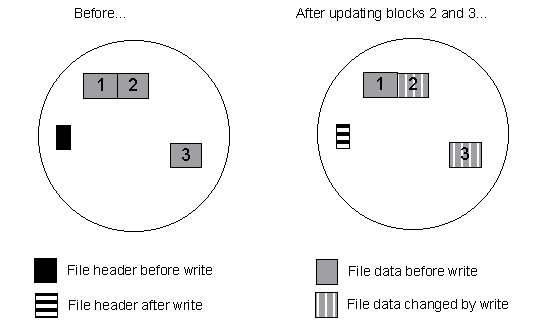
The second picture shows a similar file in an LFS, and what happens when
it is modified:
Notice how EVERYTHING that is changed is written to the END of the log. For one thing, this is much faster since the disk doesn't need to seek all over the disk to write to parts of a file, but also it's much safer because the original data blocks of the file aren't "lost" until the log has successfully written the "new" data blocks. This leads to very stable filesystems with nearly no time required after a crash.
Imagine you have some file "foo.bar" that you're going to change the contents of. The inode for "foo.bar" lists, say, 4 data blocks. The data for "foo.bar" lies at disk locations 3110, 3111, 3506, and 3507. The first thing to notice is that this file is fragmented. The hard drive will have to seek to 3100 range, read two blocks, then seek to the 3500 range and read two blocks to read the entire file. Lets say you modify the 3rd block. The filesystem will read the third block, make your changes, and rewrite the third block, still located at 3506. If you append to the file, you could have blocks allocated anywhere.
Imagine now, that you're updating a directory entry. You've just modified 15 file entries in the 5th block of some giant directory entry. Just as the disk is in the middle for writing this block, you lose power, and the block is now not complete, and totaly invalid.
During the reboot, UNIX machines run a program called "fsck" (filesystem check) that steps through the entry filesystem validating all entries and making sure that blocks are allocated correctly, etc, etc. It would find this directory entry and attempt to repair it. Who knows how successful this would be. It's possible that you could have lost all the directory entries after the one modified if things get really messed up.
For large filesystems, fsck'ing can take a very long time. Ask any net-news administrator about their news machine crashing, and find out how long it takes to fsck their 10 gig news filesystem. I've heard things in the range of 2-3 hours.
There is another type of filesystem, known as the "journaling" or "logging" file system. These filesystems keep track of _changes_ rather than the "current" contents of a file. ("Journaled" filesystems keep track only of inode changes, where as Logging filesystems keep track of changes made to both data and inodes.) In my first example with the "foo.bar" file, rather than modifying the data in the 3506 block, a logging file system would store a copy of "foo.bar"'s inode and the third block in new locations on the disk. The in-memory list of inodes would be changed to point "foo.bar" to the new inode as well. All changes and appends and deletes would be logged to a growing part of the filesystem known as the "log". Every once in a while, the filesystem would "checkpoint" and update the on-disk list of inodes, as well as freeing the "unused" parts of files (like the original third block of "foo.bar").
These filesystems, after crashing, come back online almost immediately because only the filesystem after the last checkpoint needs to be checked. All the changes in the log can be replayed quickly, and the "bad" part of the disk will always be the last change added to the log, which can be thrown away since it will be invalid, and no data is lost except for the change that was lost at power-off. That same 10 gig news filesystem would take 4 or 5 seconds to fsck after a crash.
The major problem with logging filesystems is that they can get fragmented easily. Everyone has a solution for this, and they're all different.
Logging filesystems have nearly identical read-speed because they're file data blocks are still easily locatable. The inode map has the lists of blocks, and those can be read quickly. A logging file system has _drastically_ improve write-speed because it's only appending to the same area of the disk, and never really needs to seek around looking for blocks on the disk.
Because the writing speed is improved and the recovery time is improved (rather, recover time is _nonexistant_ and guaranteed to loss-less), and the read-time is comperable (possibly a bit slower due to more fragmentation), I think it's a very useful filesystem. AIX machines use journalling filesystems, and I'm quite impressed with them. That's my big reason for wanting to see logging filesystems for Linux.