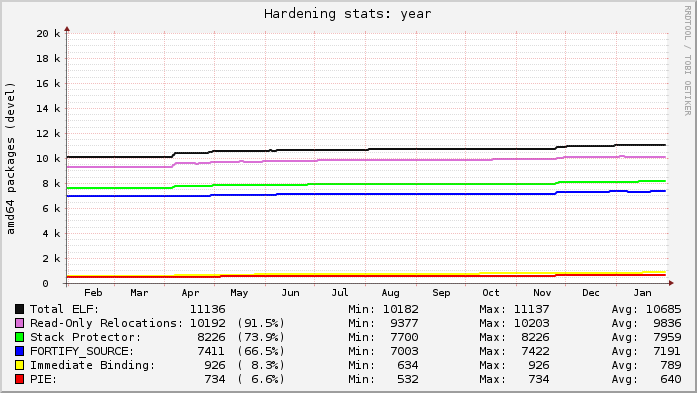
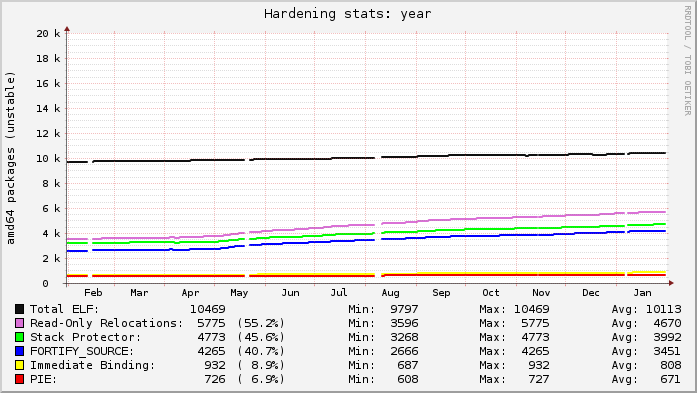
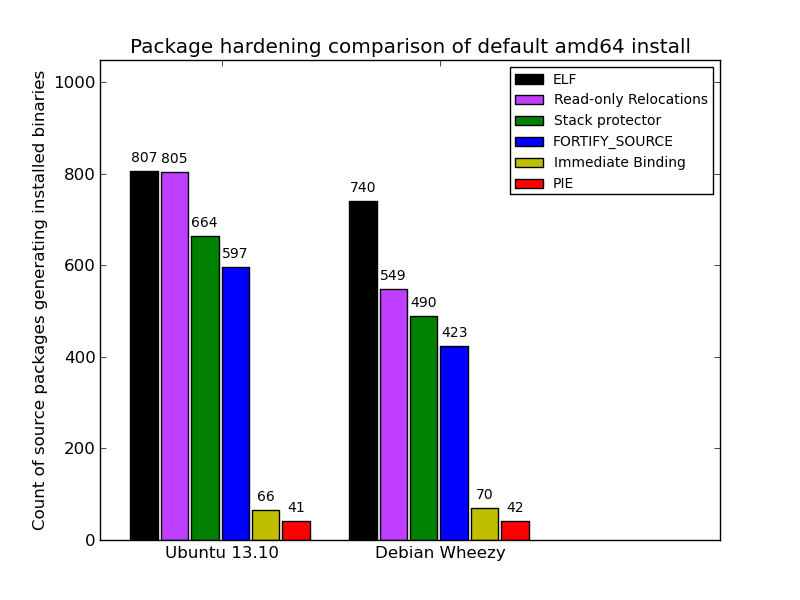
Previously: v4.8.
Here are a bunch of security things I’m excited about in the newly released Linux v4.9:
Latent Entropy GCC plugin
Building on her earlier work to bring GCC plugin support to the Linux kernel, Emese Revfy ported PaX’s Latent Entropy GCC plugin to upstream. This plugin is significantly more complex than the others that have already been ported, and performs extensive instrumentation of functions marked with __latent_entropy. These functions have their branches and loops adjusted to mix random values (selected at build time) into a global entropy gathering variable. Since the branch and loop ordering is very specific to boot conditions, CPU quirks, memory layout, etc, this provides some additional uncertainty to the kernel’s entropy pool. Since the entropy actually gathered is hard to measure, no entropy is “credited”, but rather used to mix the existing pool further. Probably the best place to enable this plugin is on small devices without other strong sources of entropy.
vmapped kernel stack and thread_info relocation on x86
Normally, kernel stacks are mapped together in memory. This meant that attackers could use forms of stack exhaustion (or stack buffer overflows) to reach past the end of a stack and start writing over another process’s stack. This is bad, and one way to stop it is to provide guard pages between stacks, which is provided by vmalloced memory. Andy Lutomirski did a bunch of work to move to vmapped kernel stack via CONFIG_VMAP_STACK on x86_64. Now when writing past the end of the stack, the kernel will immediately fault instead of just continuing to blindly write.
Related to this, the kernel was storing thread_info (which contained sensitive values like addr_limit) at the bottom of the kernel stack, which was an easy target for attackers to hit. Between a combination of explicitly moving targets out of thread_info, removing needless fields, and entirely moving thread_info off the stack, Andy Lutomirski and Linus Torvalds created CONFIG_THREAD_INFO_IN_TASK for x86.
CONFIG_DEBUG_RODATA mandatory on arm64
As recently done for x86, Mark Rutland made CONFIG_DEBUG_RODATA mandatory on arm64. This feature controls whether the kernel enforces proper memory protections on its own memory regions (code memory is executable and read-only, read-only data is actually read-only and non-executable, and writable data is non-executable). This protection is a fundamental security primitive for kernel self-protection, so there’s no reason to make the protection optional.
random_page() cleanup
Cleaning up the code around the userspace ASLR implementations makes them easier to reason about. This has been happening for things like the recent consolidation on arch_mmap_rnd() for ET_DYN and during the addition of the entropy sysctl. Both uncovered some awkward uses of get_random_int() (or similar) in and around arch_mmap_rnd() (which is used for mmap (and therefore shared library) and PIE ASLR), as well as in randomize_stack_top() (which is used for stack ASLR). Jason Cooper cleaned things up further by doing away with randomize_range() entirely and replacing it with the saner random_page(), making the per-architecture arch_randomize_brk() (responsible for brk ASLR) much easier to understand.
Edit: missed this next feature when I first posted!
User namespace restrictions
Eric Biederman landed a sysctl to control how many user namespaces can be created (on a per-user and per-namespace basis) via /proc/sys/user/max_user_namespaces. The ability to limit access to user namespaces has been desired for a while, since a large amount of attack surface gets exposed from within a user namespace, due to it allowing various interfaces to operate within the namespace that were originally limited to the true root user before. A system can now disable user namespaces by writing 0 to the sysctl.
That’s it for now! Let me know if there are other fun things to call attention to in v4.10.
© 2016 – 2017, Kees Cook. This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 License.